

摘要:内存划分包括堆和栈的设计,旨在解决程序运行时的数据存储和管理问题。堆主要用于动态内存分配,为程序提供灵活的空间以存储大量数据或对象。栈则用于存储局部变量和函数调用的临时数据,保证数据的快速存取和程序流程的有序性。通过这种内存划分,解决了静态与动态数据存储需求、局部与全局数据的管理问题,提高了程序的运行效率和稳定性。
本文目录导读:
在计算机科学中,内存管理是一项至关重要的技术,为了更好地管理和使用内存资源,开发者们将内存划分为多个部分,其中最为常见的两种划分方式就是堆(Heap)和栈(Stack),这两种内存区域各自具有独特的特性和用途,对于程序的运行和性能有着重要影响,本文将探讨为何内存需要划分为堆和栈,以及当初设计这两个区域时分别要解决什么问题。
内存划分的必要性
在理解为何内存需要划分为堆和栈之前,我们首先需要明白,计算机程序在运行过程中需要处理大量的数据,这些数据需要在内存中存储,由于内存管理的复杂性,如果不进行内存划分和有效管理,可能会导致程序运行效率低下,甚至出现内存泄漏、野指针等问题,为了更好地管理和使用内存资源,提高程序的运行效率,开发者们将内存划分为堆和栈。
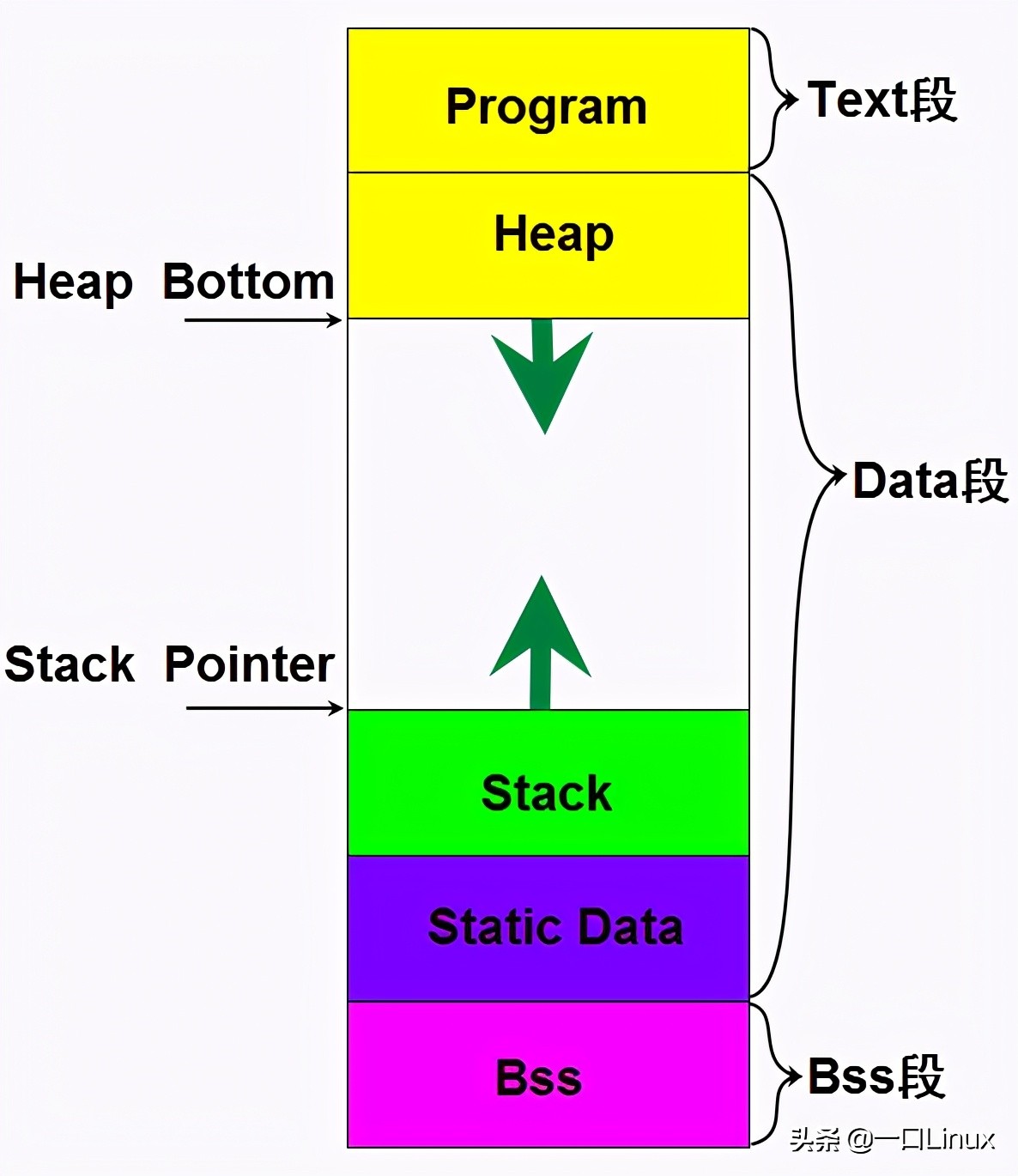
堆的设计及其解决的问题
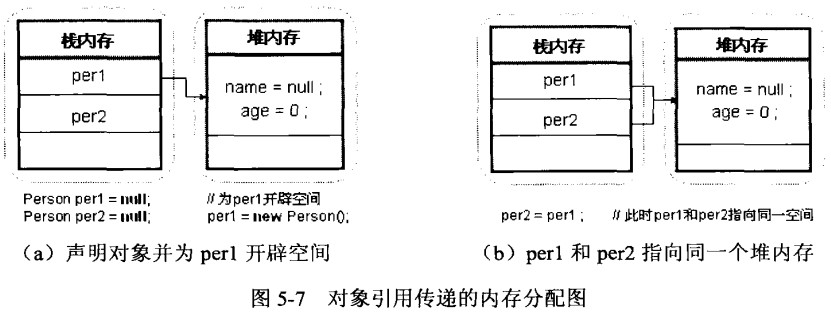
堆内存区域主要用于动态内存分配,在程序运行过程中,堆为动态分配的对象(如C++中的new操作或Java中的new关键字)提供存储空间,与栈不同,堆的大小通常更大,且其管理更为复杂,设计堆的主要目的是解决以下问题:
1、提供动态分配的空间:程序在运行过程中,有时需要创建大小不定的数据结构,如动态数组、链表等,这些数据结构需要在运行时动态分配内存空间,堆为这些数据结构提供了动态分配的空间。
2、解决内存泄漏问题:通过堆进行动态分配的内存空间,在不再使用时需要手动释放,这可以避免因内存泄漏导致的性能问题,通过合理的内存管理策略,开发者可以有效地管理堆内存的使用。
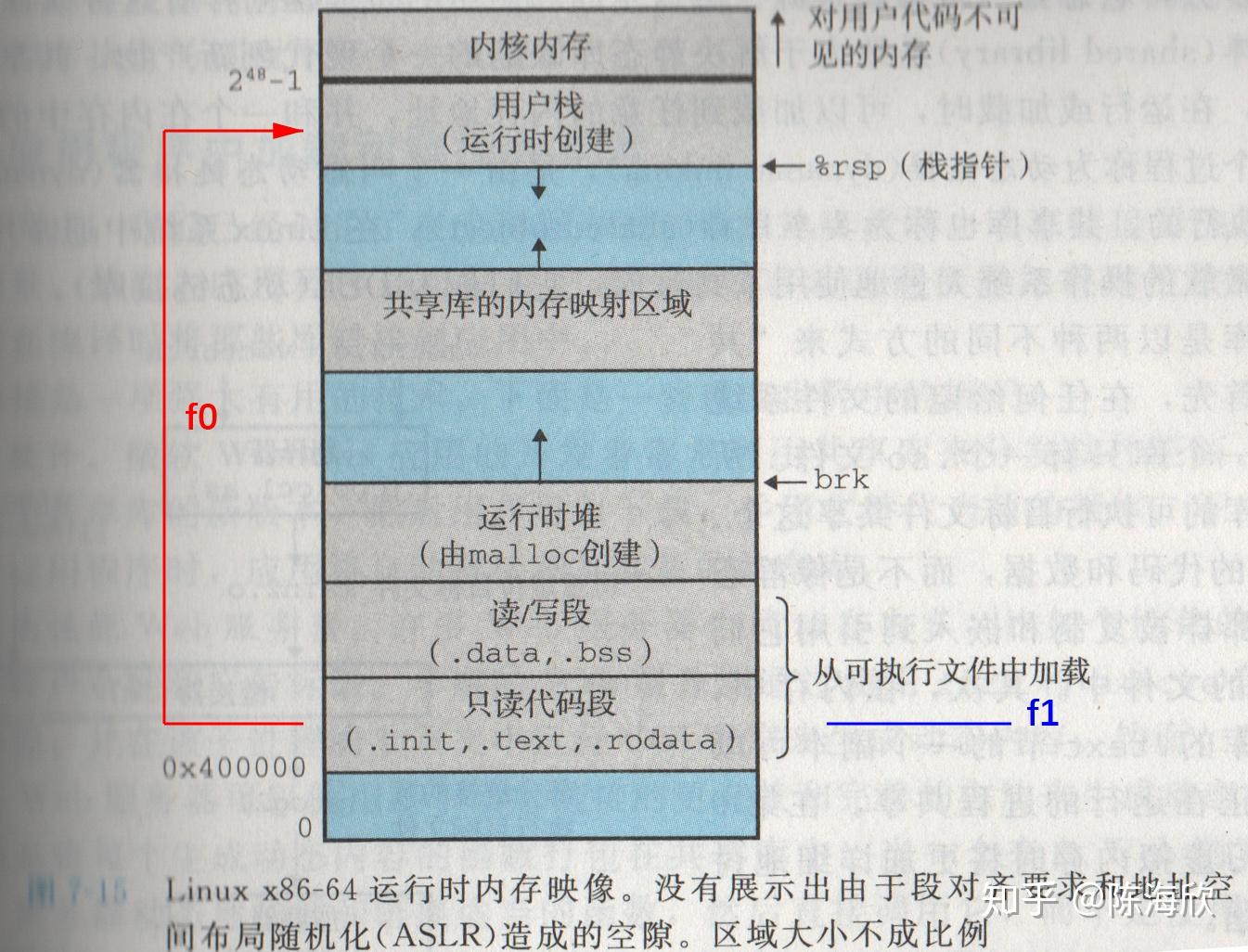
栈的设计及其解决的问题
栈内存区域主要用于存储局部变量、函数参数以及函数调用过程中的临时数据,栈的特性是后进先出(LIFO),这使得栈在存储和检索数据方面具有高效性,设计栈的主要目的是解决以下问题:
1、提高数据访问效率:栈采用LIFO策略,这使得最近使用的数据总是位于栈顶,可以快速地访问和修改这些数据,这对于提高程序的运行效率至关重要。
2、局部变量和函数调用的管理:在程序运行过程中,函数需要存储其参数、局部变量以及返回地址等信息,这些信息可以通过栈来管理,当函数调用完成时,栈可以快速地清理这些数据,从而节省内存空间。
内存划分为堆和栈是计算机程序设计和开发过程中的一项重要技术,通过划分内存区域,我们可以更好地管理和使用内存资源,提高程序的运行效率,堆主要用于动态分配的内存管理,以解决动态数据结构的存储和内存泄漏问题;而栈则主要用于存储局部变量、函数参数以及函数调用过程中的临时数据,以提高数据访问效率和进行局部变量及函数调用的管理,通过理解堆和栈的设计初衷及其解决的问题,我们可以更好地进行内存管理,提高程序的性能和稳定性。
 京公网安备11000000000001号
京公网安备11000000000001号 豫ICP备2020027693号-1
豫ICP备2020027693号-1